
Don’t Fall for Another AI Hype Trap: What It Really Takes to Build Agentic AI
Cutting through the noise of toy agents to reveal what automation at scale really demands


It’s becoming almost cliché to hear about Agentic AI and AI Agents, especially now that the shine has worn off of LLMs. The market is filling up with familiar re-branding games including vendors slapping a new label on old connectors, adapters, and integrations and calling them “agents.” Others are selling “LLM wrappers,” lightweight scripts that rent a bit of statistical reasoning and masquerade as automation. Add to this to the flood of tutorials that teach you how to chain an API call or wrap a couple of prompts around an LLM, and suddenly everything looks “agentic.”
To be blunt, this isn’t enterprise AI. It’s toy-level automation dressed up for a new hype cycle.
Agentic AI ≠ AI Agent
The terms are being conflated, but they are not even in the same league. An AI Agent, as most vendors describe it, is a disposable worker. It executes a task, passes along an output, and disappears. Useful, yes, but limited.
Agentic AI is an ecosystem. It is the scaffolding, orchestration, and intelligence required to automate at enterprise scale in industries like finance, healthcare, industrial automation, life sciences, and defense. It’s not about happy paths where data is clean, workflows are linear, and exceptions are rare. It’s about the messy reality:
Fragmented data spread across hundreds of systems.
Omissions and missing details that require conditional fetching.
Errors, anomalies, and exceptions that humans spend most of their time untangling.
Enterprises don’t operate in neat straight lines. They operate in fractals of complexity, and Agentic AI exists to tame that chaos one request at a time.
Automating Complexity, Not Happy Paths
In real deployments, Agentic AI must handle millions of tasks seamlessly:
Catching errors and recovering without bringing workflows down.
Reconciling across hundreds of systems that must remain synchronized.
Massaging data into the right formats, syntaxes, and schemas.
Performing precise calculations where accuracy matters, not averages.
Surfacing exceptions that genuinely require human judgment, while closing the loop on everything else with a level of assurance equal to a human expert.
This isn’t “magical” AI that learns everything on its own. We made that mistake with LLM hype. Enterprises cannot afford to make it again.
Why AI Agents Should Stay “Dumb”
Ironically, the more we try to make individual agents “intelligent,” the less reliable enterprise automation becomes. Agents should be relatively dumb: execute a specific task, return results, and get out of the way. The intelligence belongs in the Agentic AI framework—the orchestration layer, the shared memory, the secure data, the policies, the symbolic reasoning engines that impose determinism on probabilistic models.
It’s here that machine learning models and symbolic AI methods must work together to ensure compliance, observability, and reliability. This is what prevents automation from devolving into chaos when 10,000 agents fan out across an enterprise landscape of 800+ systems and thousands of use cases.
The Agentic Illusion
The diagram below illustrates the illusion vendors want you to buy into: that building agents and flows is simple. A few API calls chained to an LLM, and suddenly you’ve “automated the enterprise.” It’s a tidy story, but it’s fiction.
This is the simplistic view of developing and stitching together AI agents where you can connect System A to System B through a wrapper, drop in some prompt engineering, and let the LLM fill in the blanks. It looks plausible in a demo. It looks neat in a training video. But it ignores the real-world complexity of enterprise operations.
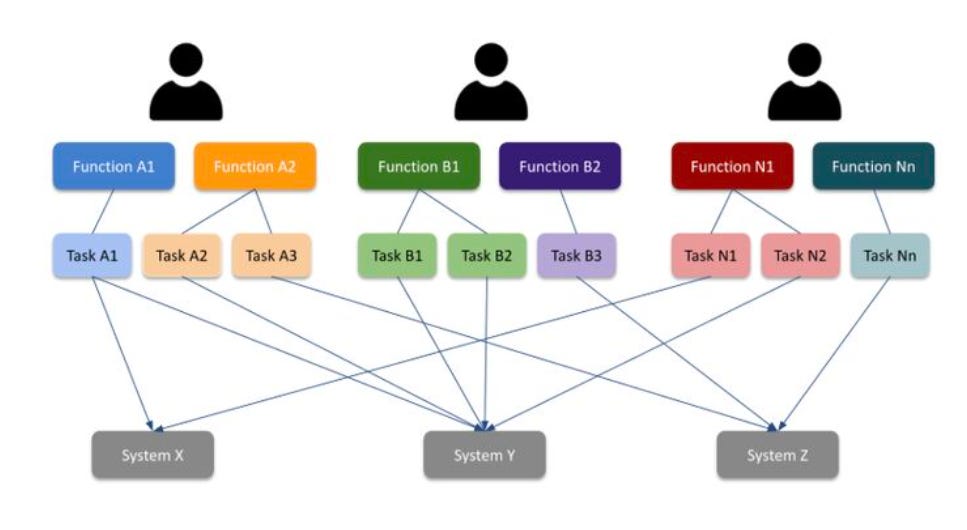
In a large enterprise, automation doesn’t mean two or three systems exchanging data. It means orchestrating across hundreds of internal and external systems, each with its own data formats, APIs, error modes, and compliance requirements. It means handling thousands of edge cases — from missing records, to stale credentials, to policy conflicts, to data arriving out of sequence. And it means navigating trip points that only reveal themselves after years of scars from failed automation attempts.
Agentic AI is not about shortcuts. It’s about building adaptive, intelligent systems that can survive the brutal complexity of enterprise workflows and deliver automation you can trust. Anything less is just another chapter in the hype cycle.
What Real Agentic AI Demands
True Agentic AI is adaptive, multi-layered, and recursive. A single enterprise request can explode into thousands of discrete tasks that must be orchestrated, choreographed, sequenced, retried, and load-balanced. These aren’t trivial background jobs. They involve pulling data from dozens, sometimes hundreds, of internal and external systems, breaking that data into fragments, reasoning across those fragments, and then feeding results back into other agents that re-reason before deciding the next move. It’s multi-hop reasoning with orchestration and aggregation at every step.
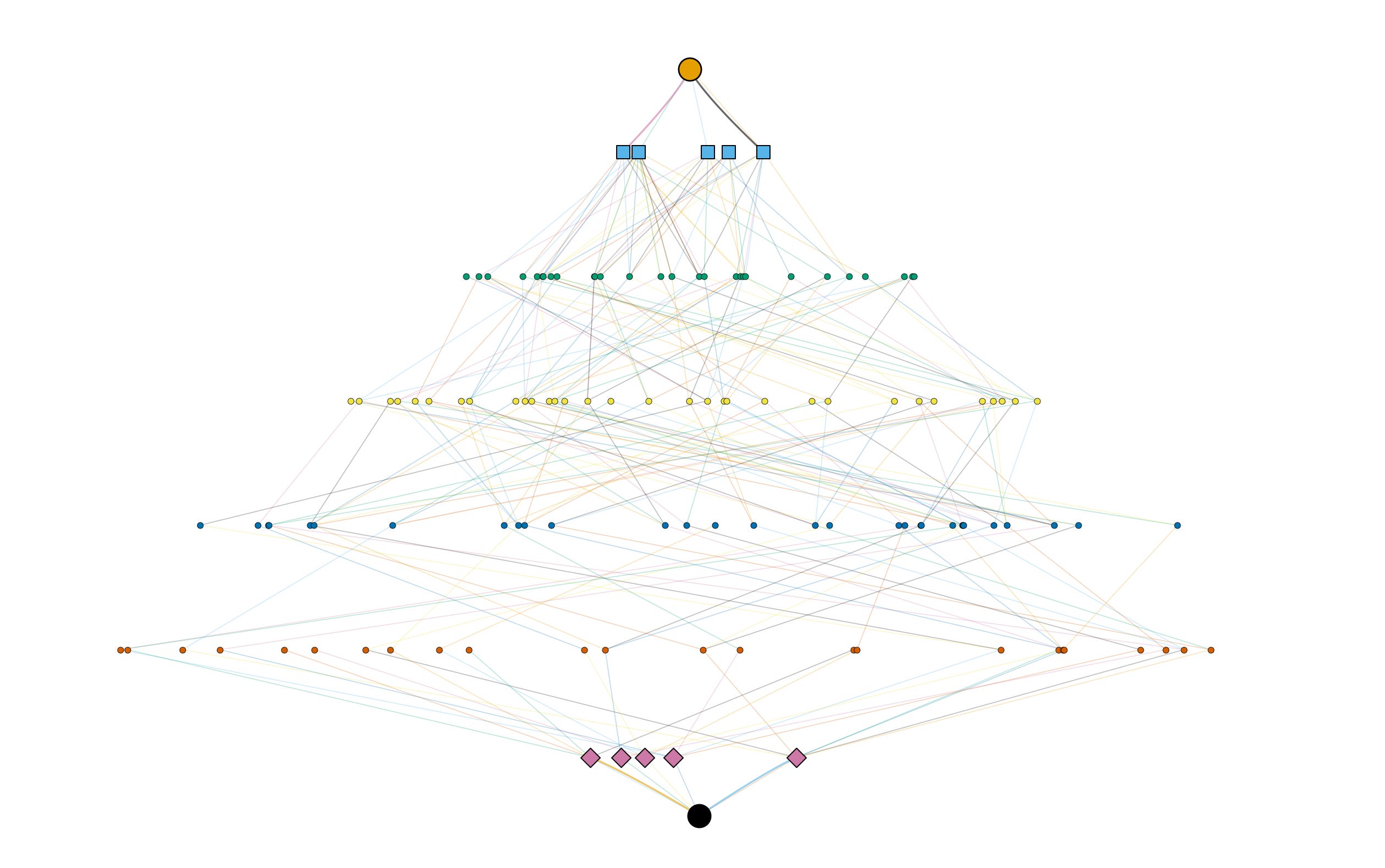
This doesn’t look like a neat straight line. It looks like a branching forest:
Multiple agents feeding results into other agents for higher-order reasoning.
Parallel tasks fanning out across systems, only to collapse back into aggregation points.
Layers upon layers of orchestration determining what to do next and under what conditions.
Take the case of generating a single Charli financial due diligence report that can take over 5,000 tasks. This agentic AI process draws on data from regulatory filings, external financial data feeds, internal financial systems, news feeds, web sources, customer databases, and partner datasets that can measure in exabytes. Each source has its own format, quality issues, and update cycles. Data must be qualified through separate pipelines, reconciled into coherent fragments, and then reasoned over multiple times to construct an accurate view. And because enterprises live under audit, the system must preserve lineage such that an auditor seven months later can know exactly what data fragment was considered, where it came from, and when it was ingested.
Contrast that with the consumer world, where the default pattern is to RAG a handful of documents into an LLM and ask for a summary. That’s not enterprise automation reality. In enterprises, data must be intelligently curated into multiple reasoning contexts, cross-referenced, and validated. How does a news article reconcile with a regulatory filing? How does that tie back to financial statements stored in a separate ERP? They don’t line up neatly. But each fragment contributes meaning to the reasoning process. And in regulated industries, it’s not enough for the AI to “get it right”—it must explain what fragment of what content was used to reach the answer.
Add in the ability of the AI to perform actions including system updates, record changes, and notifications — and you need to get it right.
The Scale of Complexity
And that’s just one reasoning tree (or more accurately, a branching forest). In real-world production environments, there are hundreds of these trees running in parallel, each with nested steps, nested layers, and recursive reasoning loops.
A useful analogy is to think of each reasoning tree as a specialized team within an organization. Each team is working through a subset of the problem—validating data, reconciling numbers, cross-referencing external content—and, just like in an enterprise, these “teams” need to collaborate. Results have to be exchanged, compared, and aggregated into a coherent whole the business can trust. Orchestration and aggregation never stop—they are continuous processes that stitch together the contributions of many reasoning trees into a single, reliable outcome.
The integration footprint required to support this is staggering. Every enterprise system—ERP, CRM, financial ledgers, regulatory archives, document repositories, partner APIs—must be queried, updated, reconciled, and frequently re-validated through secondary and tertiary systems. And these integrations are rarely generic plug-ins. They are bespoke pipelines with transformations and data dependencies unique to each system of record. Even small mismatches in schema, timing, or semantics can propagate errors downstream, triggering cascading failures or creating blind spots in compliance.
This is why even seemingly simple requests—“generate a compliance report,” “update a portfolio view,” or “process a claims exception”—are anything but trivial. What looks like a single query on the surface can fan out into thousands of underlying agentic tasks: pulling from dozens of systems, reconciling conflicting data, applying policies, retrying partial failures, and consolidating results.
Each one of those tasks requires precision, traceability, and governance. Without them, a single silent error—a misapplied transformation, a missing data fragment, a failed sync—can ripple outward, creating material risk across the organization. In regulated industries, that’s not just a technical issue; it’s a business liability.
A Watchful Eye
We’ve said it before, but it bears repeating: governance in Agentic AI is not optional. When thousands of tasks are firing across interconnected systems, risks don’t add up linearly, they compound exponentially. Data drift, silent partial failures, inconsistent state updates, and compliance blind spots don’t just create operational noise; they erode trust in the entire automation fabric. Without preventive controls, observability, and self-healing, the system is untrustworthy.
And governance here doesn’t just mean a dashboard with pretty graphs. It means deep instrumentation at every layer:
Explainability at the fragment level, so you know exactly which data contributed to which decision.
Deterministic scaffolding wrapped around probabilistic reasoning models, so outcomes can be made auditable and repeatable.
Policy enforcement baked into orchestration, so compliance is not an afterthought but a first-class property of the system.
In practice, this looks like the orchestration layer maintaining complete visibility into the agentic flow—from the data inputs and outputs, to the security and access controls, to the sequencing of tasks. It has the authority to pause, adjust, retry, or reroute as conditions change, and it can surface errors with the precision needed for root-cause analysis.
The screen capture below illustrates this level of transparency: a snippet of an Agentic AI process showing the steps executed, the rationale behind them, and the data dependencies involved. Each task is annotated with its required inputs, its produced outputs, and a traceable lineage of how those fragments flow through the system. This is what it takes to make an AI-driven enterprise system not only perform but also govern itself responsibly.

This level of transparency is not a luxury. It is a survival requirement for enterprises operating in regulated, mission-critical environments.
So when CIOs, CTOs, or boards ask: “Why does enterprise Agentic AI require such complex governance?” —this is the answer. Because without it, you don’t have enterprise-grade automation. You have another dressed-up demo destined to collapse under real-world complexity.
Rethinking AI Infrastructure to Unlock New Insights in Capital Markets